Backup vs. Replication
People often confuse the terms backup and replication, but there are several distinctions:
- Backup solutions keep a history of the data whereas replication only keeps the latest state of the data.
- In case of a crash/outage/hardware failure, a replication solution will have the latest image of the data whereas a backup solution will only have the latest backup, whenever it was performed.
- If a logical data loss scenario occurs, like a human error (someone accidentally deleted necessary data) or a malicious attack, the replication solution will automatically reflect that data loss to the other replica, and thus will not be helpful. A backup solution will have the latest backup before the data loss occurred.
- Backup solutions are typically cheaper and require less bandwidth.
There is another kind of backup solutions called CDP (continuous data protection). These solutions record every IO on a protected disk, and can go back and recover to any point in time. These solutions are also typically expensive. Snapshot technology allows taking snapshots at a frequent rate, and solutions leveraging this capability are sometimes referred to as near-CDP solutions.
EBS Snapshots as a near-CDP solution
When production data is stored on EBS volumes, it is possible to leverage the EBS snapshot technology to implement a backup solution, but snapshot technology also allows taking snapshots at a frequent rate (ear-CDP), and that can bring the solution to be very near a replication based high availability solution. It’s all a matter of RPO (Recovery Point Objective) and RTO (Recovery Time Objective).
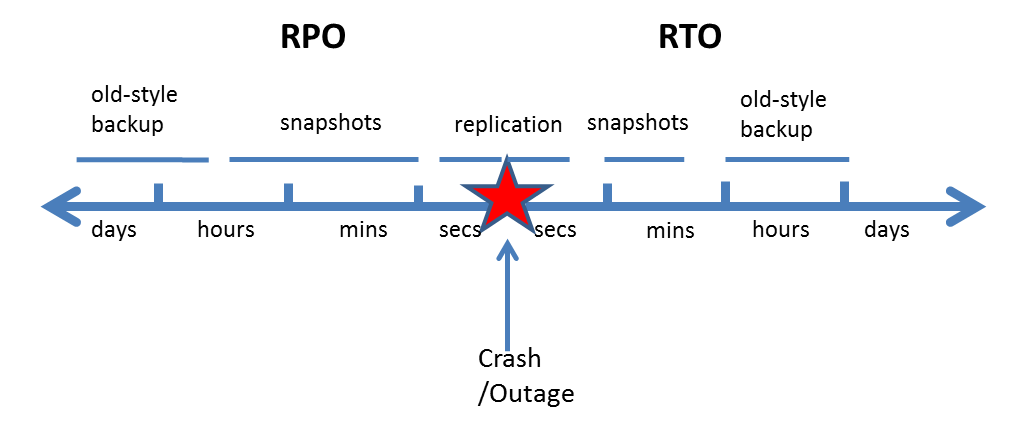
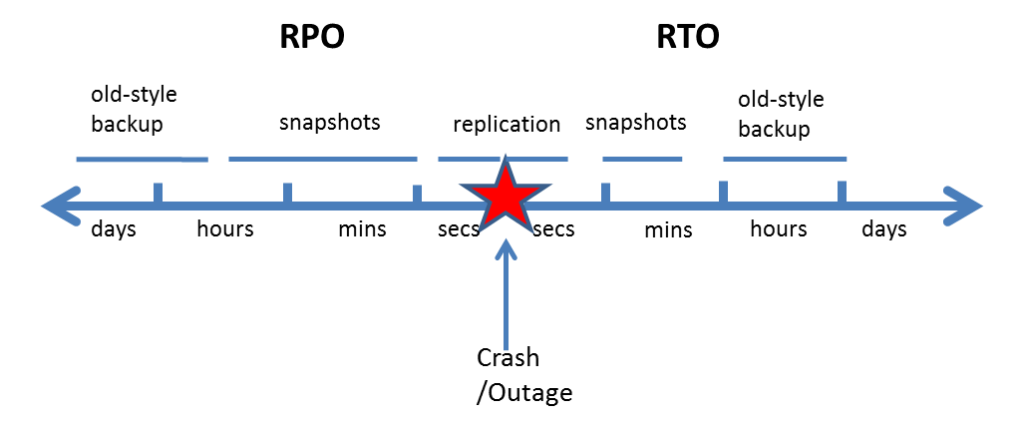
RPO means how recent the data will be if a recovery is needed. RTO mean how fast the recovery process takes, or in other words, how much downtime will a system experience when a crash/outage occurs, until the recovery process is complete. Naturally one strives to minimize both RPO and RTO, and data protection technologies have different capabilities in terms of RPO & RTO:
As can be seen from the diagram, a replication (or high availability) solution gives the shortest possible RPO and RTO in case of a crash or outage. What is also clear is that snapshot technology has only a slightly longer RPO & RTO. In the EC2 environment with EBS snapshots, it is possible to take snapshots at varying frequencies. It’s even possible to take snapshots minutes apart, if you have a suitable snapshot management solution, like N2WS Backup & Recovery, that can handle it.
What’s especially cool about it is that the incremental nature of EBS snapshots allows taking frequent snapshots without a big impact on the cost of storing the snapshots or on the time it takes to complete them. EBS snapshots also give the ability to recover complete instances with all their data almost instantly, so RTO should not be a problem. So, it boils down to business needs of applications (as usual). An application that can stand a certain amount of downtime and a certain loss of data when recovering can use snapshots rather than a replication based high availability solution. A snapshot-based solution will give all the advantages of a backup solution plus a near-CDP poor man’s high availability solution.
You need backup anyway…
One needs to keep in mind that a backup solution is needed anyway. Even if a replication-based solution is implemented, there is still the need to defend against logical data loss scenarios. The following table summarizes all the possibilities: backup without replication, replication without backup, snapshot-based backup vs. old file-level backup solutions and using snapshots for near-CDP/poor man’s high availability snapshots.
It’s hard to put an exact price tag on each solution so prices are just represented by a number from 1 (cheapest) to 5 (most expensive). File-level backup solutions are typically more expensive than snapshots based since they are less efficient in terms of CPU and data reduction (snapshots are incremental by nature). Replication costs a lot in terms of bandwidth and also any hot standby systems on the remote site.
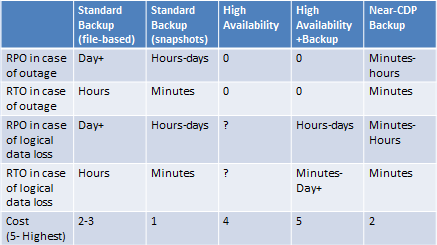
It is clearly visible from the table, that in terms of cost-effectiveness, the poor man’s high availability is the best solution. But it can be used only if a strict high-availability solution is not required.