
What Is Data Backup?
Data backup is the process of creating copies of important data to safeguard against data loss, corruption, or accidental deletion. These copies are stored in a separate location from the original data to provide a safety net in case of data disasters. The backup process can be automated and scheduled to run at regular intervals, such as daily, weekly, or monthly, depending on the organization’s needs and the criticality of the data.
This is part of a series of articles about cloud backup services
Backups can be created using different methods
- Full backup: This involves copying all data every time a backup is performed. It requires significant storage space and time.
- Incremental backup: This only backs up data that has changed since the last backup, reducing storage requirements and time but requiring a complete chain of previous backups for a full restore. (Except when using a tool like AWS Backup or N2W, where each backup, though incremental, retains the necessary reference data to allow a full restore, even if the original (full) backup has reached the end of its lifecycle and been deleted.)
- Differential backup: Similar to incremental, but it backs up all changes made since the last full backup, striking a balance between storage space and restore time.
The primary objective of data backup is to ensure that data can be restored to its previous state following a data loss event, such as hardware failure, cyber-attacks, or natural disasters. Backups are essential for disaster recovery and long-term data retention, as well as compliance with data protection regulations.
What Is Data Replication?
Data replication involves copying and maintaining data in multiple locations to ensure high availability and consistency. Unlike backups, replication focuses on real-time or near real-time data synchronization across different systems or geographic locations. This ensures that any changes made to the original data are immediately reflected in the replicated copies.
There are several types of data replication
- Synchronous replication: Data is simultaneously written to both the primary and secondary locations. This ensures data consistency but may introduce latency.
- Asynchronous replication: Data is first written to the primary location and then replicated to secondary locations. This reduces latency but may result in slight delays in data consistency.
- Snapshot replication: Periodic snapshots of data are taken and replicated. This method balances the need for up-to-date data with system performance considerations.
Learn more about snapshots in our EBS snapshot guide.
The goal of data replication is to enhance data availability, support load balancing, and ensure quick failover in case of system failures. Replication is required for business operations that require uninterrupted access to data, such as eCommerce platforms and financial services.
Data Backup vs Data Replication: The Key Differences
1. Purpose
Data backup aims to create a safety net against data loss and corruption. Backups enable data restoration from a specific point in time, making them useful for disaster recovery, archives, and compliance with data retention policies. They allow an organization to recover its data and resume operations after a data loss incident.
Data replication aims to ensure high data availability and consistency across multiple systems or locations. The focus is on maintaining real-time data synchronization to minimize downtime and enable seamless failover during system failures. Replication is important for business continuity, ensuring that operations can continue without interruption.
2. The Process
Data backup involves periodically copying data to a backup storage system. This process can be manual or automated, and is typically scheduled to run during off-peak hours. Backup methods include full, incremental, and differential backups, affecting storage space, backup time, and restoration complexity. Backups are usually stored in secure, off-site locations, such as cloud storage, dedicated backup servers, or external hard drives.
Data replication continuously copies data from one system to another in real-time or near real-time. This requires strong network connectivity and replication software to manage data and ensure consistency. Replication can be synchronous or asynchronous, offering different levels of data consistency and latency. The replicated data is often stored in geographically distributed data centers to enhance disaster recovery capabilities and support global operations.
3. Recovery Point Objective (RPO) and Recovery Time Objective (RTO)
RPO and RTO are important parameters organizations consider in their business continuity strategy.
Replication strives to keep RPO close to zero, which means that if you need to recover, the data will be (almost) available in its most updated state.
With backup, RPO depends on frequency of backups. You can only go back to your most recent copy of the data. With modern snapshot-based backup solutions, backup can be very frequent, and can reduce the RPO to minutes.
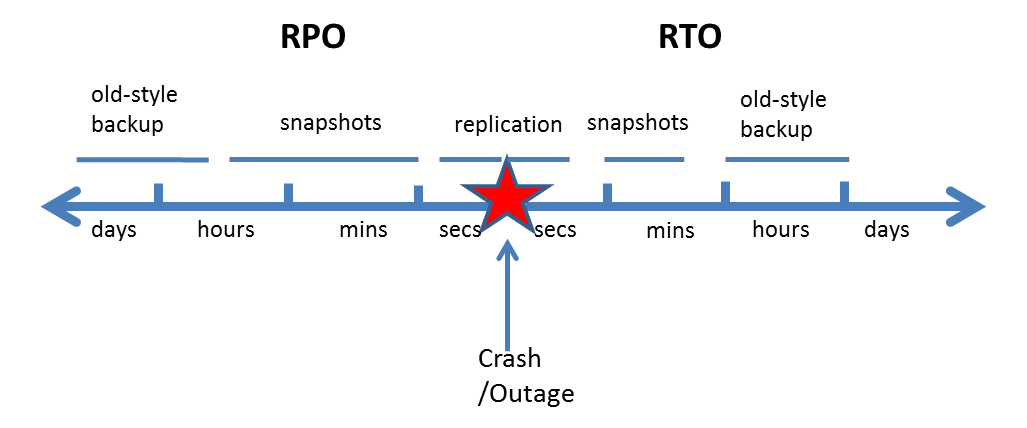
As for RTO. Traditional replication solutions kept a “hot standby” system and could recover immediately, as opposed to backup solutions which needed to copy the data back into the primary storage, an operation that could take hours or even days.
With modern snapshot-based solutions, recovery of servers and data takes seconds to minutes, so recovery is almost immediate. Therefore, with modern solutions, no significant difference currently exists between replication and backup solutions in terms of RTO.
✅ TIP: N2W allows you to achieve near-zero RTO with easy, reliable recovery in seconds.
4. Requirements
Data backup requires adequate storage capacity to hold multiple versions of data over time. This can include on-site storage solutions, off-site storage facilities, or cloud-based services. Backup solutions also require reliable backup software to manage the scheduling, execution, and restoration of backups. Organizations must protect backup data from unauthorized access.
Data replication requires high network bandwidth and low latency to propagate data changes quickly across systems. Replication software manages the synchronization process, handles conflict resolution, and maintains data consistency. It often involves geographically distributed data centers to improve data availability. Organizations must consider data consistency models, such as eventual consistency or strong consistency.
5. Use Cases
Data backup is suitable for scenarios requiring data protection from loss due to corruption, accidental deletion, or cyber-attacks. Common use cases include disaster recovery, long-term archival storage, and compliance with regulatory requirements for data retention. Organizations use backups to restore data to a known good state after incidents such as hardware failures, ransomware attacks, or natural disasters.
Data replication is suited for applications that demand high availability and minimal downtime. Typical use cases include online transaction processing systems, content delivery networks, and distributed databases. Replication supports load balancing by allowing multiple systems to handle user requests simultaneously. It is also useful for business continuity planning, enabling organizations to maintain operations during system failures or maintenance windows.
6. Costs
Data backup costs include expenses for storage media, backup software, and off-site or cloud-based storage services. On-site storage solutions may require upfront costs for hardware, while cloud-based backup services typically involve recurring subscription fees based on data volume and backup frequency. There are also operational costs for managing and maintaining backup systems.
🤑 TIP: To reduce the costs of storing backups longterm, choose a tool like N2W, which allows you to automatically archive snapshots into any Amazon S3/Glacier tier for up to 92% cost savings.
Data replication costs can be higher due to the need for strong network infrastructure and replication software. Organizations must invest in high-speed network connections and sufficient storage capacity to maintain synchronized copies of data. There are also ongoing operational costs for monitoring and managing replication processes, handling conflicts, and transferring data between geographic locations. In the cloud, data replication is simpler to achieve, and is typically offered as an add-on service to cloud-based storage and backup services.
Here are 5 tips that can help you better implement and optimize data backup and replication strategies:

Backup vs. Replication: How to Choose?
When deciding between data backup and data replication, several key considerations can guide your choice:
🎯 Data recovery objectives
- Data backup:
- Suitable for organizations focused on restoring data to a specific point in time following data loss.
- Suitable for disaster recovery, long-term data retention, and compliance with regulatory requirements.
- Data replication:
- Suitable for applications requiring high availability and minimal downtime.
- Ensures continuous access to data and supports failover during system failures.
⏱️ Frequency and timing
- Data backup:
- Typically performed at scheduled intervals (e.g., daily, weekly).
- Best suited for non-real-time data recovery scenarios.
- TIP: N2W gives you the ability to backup in 60 second intervals, which might be enough so that you don’t need a data replication tool.
- Data replication:
- Provides real-time or near real-time data synchronization.
- Useful for operations requiring immediate data consistency in multiple locations.
📈 Performance impact
- Data backup:
- Can impact system performance during backup operations, especially if performed during peak hours.
- Usually scheduled during off-peak times to mitigate this.
- Data replication:
- Requires network and system resources to maintain continuous data synchronization.
- May introduce latency, particularly with synchronous replication.
🗄️ Storage requirements
- Data backup:
- Requires substantial storage capacity for multiple versions of data, including full, incremental, and differential backups.
- Often involves off-site or cloud storage solutions.
- Data replication:
- Requires maintaining live copies of data across multiple locations.
- Storage needs depend on the volume of data and the replication strategy (synchronous or asynchronous).
🛜 Network bandwidth
- Data backup:
- Lower bandwidth requirements compared to replication, as backups are less frequent and can be scheduled to avoid network congestion.
- Data replication:
- High bandwidth is required to ensure real-time data synchronization, especially for geographically distributed systems.
In many cases, organizations may benefit from a combination of data backup and replication strategies.
Cloud-Based Backup and Replication with N2W
N2W offers a robust solution that combines the advantages of both backup and replication, providing organizations with near-zero recovery time objectives (RTO) while incorporating cost-saving features. As a cloud-native platform, N2W is designed specifically for AWS and Azure environments, making it an ideal choice for enterprises looking to leverage the cloud for their disaster recovery needs.
Related: read our comparison of top enterprise cloud backup tools.
Unified Backup and Cross-Region Recovery
N2W enables organizations to perform frequent, automated backups of their data with customizable policies and retention schedules. This ensures that data is consistently protected and readily available for restoration to recent points in time, which is crucial for recovering from data corruption, accidental deletions, or cyber-attacks.
Additionally, N2W supports cross-region backup and recovery, allowing for the synchronization of critical workloads across multiple cloud regions. This approach ensures quick failover capabilities, which are essential for high-availability applications and minimal downtime requirements.
Cost Efficiency
Unlike traditional hot-hot replication setups that can be costly due to the need for continuous operation of multiple active sites, N2W offers a more cost-effective alternative. By leveraging its backup capabilities, N2W minimizes the need for constant data synchronization and live resource allocation, reducing operational expenses.
The platform also optimizes storage usage through incremental backups and data archiving into low cost storage tiers, which lower the overall costs. Furthermore, N2W’s pay-as-you-go pricing model aligns with the cloud’s inherent cost-saving benefits, ensuring that organizations only pay for the resources they use.
Advanced Features
N2W extends its value with features like file-level recovery, cross-region and cross-cloud disaster recovery, and real-time alerts. The file-level recovery allows users to restore individual files or folders without having to recover entire volumes, enhancing operational efficiency.
Cross-region and cross-cloud capabilities ensure that data can be replicated and restored across different geographic locations and cloud providers, providing a comprehensive disaster recovery strategy. Real-time alerts and detailed reporting give organizations visibility into their backup and recovery status, ensuring that any issues are promptly addressed.
