
How Do You Perform Disaster Recovery in Microsoft Azure?
Disaster recovery refers to the strategies and services that ensure an organization’s critical workloads and applications can continue to operate or quickly resume in the event of a failure.
In Microsoft Azure, disaster recovery can involve replicating data and applications from primary Azure regions to secondary locations, providing a mechanism for restoring operations with minimal downtime. In the other direction, organizations can use Azure as the target for disaster recovery, ensuring that if on-premises resources fail, they can continue using them on Azure.
This process helps protect against various types of disruptions, including natural disasters, system failures, and human errors. Using Azure’s global infrastructure, organizations can implement comprehensive disaster recovery plans that meet their recovery time objectives (RTO) and recovery point objectives (RPO), minimizing potential losses and ensuring continuous service availability.
This is part of an extensive series of guides about information security.
In this article:
- Disaster Recovery Related Solutions in the Azure Cloud
- Example: Enterprise-Scale Disaster Recovery Solution on Azure
- How to Create a Disaster Recovery Plan for Your Azure Deployments
Disaster Recovery Related Solutions in the Azure Cloud
Azure offers several solutions that can be used for data recovery.
Azure Site Recovery
Azure Site Recovery (ASR) offers services that enable the replication, failover, and recovery of virtual machines (VMs) and physical servers. It supports a range of workloads, enabling seamless migration between different environments, such as Azure to Azure, on-premises to Azure, or between different on-premises locations.
The service simplifies the disaster recovery process by automating replication and failover tasks. With ASR, organizations can easily configure recovery plans within the Azure portal, reducing the complexity traditionally associated with disaster recovery operations. Additionally, ASR provides continuous health monitoring and customizable recovery plans, allowing organizations to achieve their desired RTO and RPO.
Azure Backup
Azure Backup offers a simple, secure solution for protecting data in the cloud and on-premises environments. By automating the backup process, it reduces the risk of data loss due to human error, system failures, or cyberattacks. This service supports a range of Microsoft environments, including Azure Virtual Machines (VMs), SQL databases, and SharePoint servers, ensuring protection across an organization’s digital assets.
The service provides scalable storage solutions while maintaining data encryption in transit and at rest. With Azure Backup, organizations can easily manage their backup policies and monitor backup health through the Azure portal. This simplifies the recovery process in case of data loss, enabling the restoration of services with minimal downtime.
Azure Archive Storage
Azure Archive Storage provides a cost-effective solution for long-term data retention, suitable for data that is infrequently accessed but must be retained for extended periods due to business or regulatory requirements. It uses Azure’s global infrastructure to offer secure and scalable storage options, helping reduce storage costs while ensuring data durability and security.
This service integrates with Azure’s suite of disaster recovery tools, allowing organizations to include archived data in their broader disaster recovery strategy. By using tiered storage options, including hot, cool, and archive tiers, organizations can optimize their storage costs and access patterns without compromising on the availability or integrity of their stored data.
Here are 5 tips that can help you better perform disaster recovery in Microsoft Azure:
Example: Enterprise-Scale Disaster Recovery Solution on Azure
This example is based on the Azure reference architecture for disaster recovery.
An enterprise-scale disaster recovery solution on Azure uses a combination of Azure managed services to ensure operational continuity for large organizations. This includes Azure Traffic Manager, Azure Site Recovery, and Virtual Network, among others. These services provide a framework for replicating and failing over applications hosted in an on-premises datacenter to Azure infrastructure, ensuring minimal downtime in case of disasters.
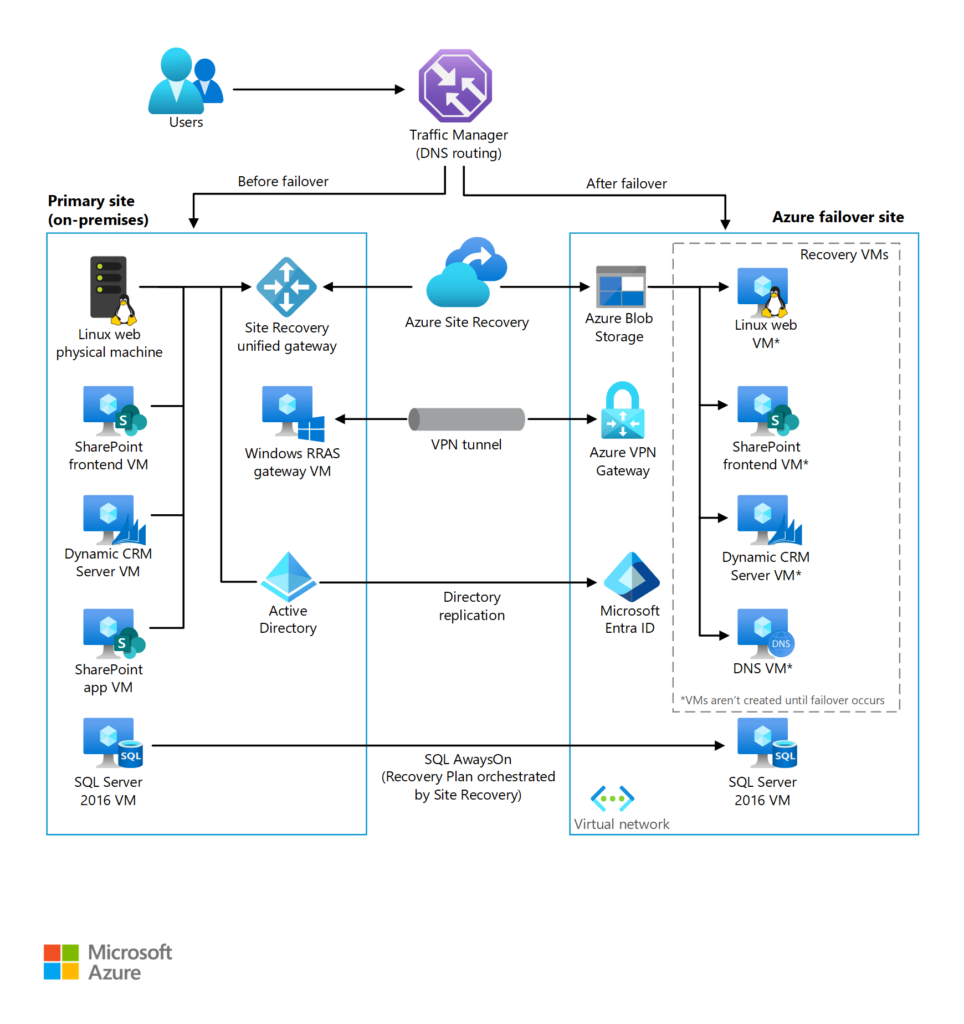
The architecture for this solution supports failover for critical applications such as SharePoint and Dynamics CRM, alongside Linux web servers. By routing DNS traffic through Traffic Manager and orchestrating replication with Site Recovery, the system ensures seamless transition during failover scenarios. This approach secures data and maintains application availability across diverse scenarios.
Key components of the solution include:
- DNS Traffic Routed via Traffic Manager: This ensures that user requests are automatically redirected to the healthy endpoint, whether on-premises or in Azure, during a failover.
- Azure Site Recovery Orchestrates Replication: ASR automates the replication of VMs, ensuring that up-to-date copies of the systems are available in the Azure region designated for disaster recovery.
- Blob Storage Stores Replica Images: Azure Blob Storage is used to store images of VMs, providing a durable and scalable repository for the replica data.
- Microsoft Entra ID Replicates On-Premises Entra ID Services: This ensures that identity and access management is consistently available, maintaining security and access controls during a failover.
- VPN Gateway: Establishes secure, encrypted connections between the on-premises datacenter and Azure, ensuring seamless connectivity during a disaster.
- Virtual Network: Provides the networking infrastructure necessary for the replicated applications to operate within Azure, mirroring the on-premises network setup.

How to Create a Disaster Recovery Plan for Your Azure Deployments
Creating a disaster recovery plan in Azure involves the following steps.
1. Assess Mission-Critical and Non-Critical Flows
In the initial planning phase, it’s essential to differentiate between mission-critical and non-critical system and user flows.
Mission-critical flows are those whose disruption would immediately impact business operations, potentially leading to significant financial losses or security risks. These typically include core services such as transaction processing systems, customer databases, and key application functionalities that directly affect service delivery.
Non-critical flows, while important, do not have an immediate impact on business continuity if disrupted. These might include internal reporting systems or batch processing jobs that can tolerate longer downtimes without causing significant business harm.
2. Create a Failure Mode Analysis Process
Failure Mode Analysis (FMA) is a systematic process aimed at identifying potential failure points within an organization’s IT infrastructure and applications. By analyzing these potential failures, IT teams can proactively design strategies to mitigate the impact of such failures on business operations.
This process involves a detailed examination of each component within the system, assessing how and where things might go wrong, and the likely consequences of each type of failure. Implementing FMA requires a thorough understanding of the system architecture, including dependencies between different components and processes.
Teams must identify critical paths in their operations and consider both internal and external factors that could disrupt those paths. Once potential failures are identified, mitigation plans can include introducing redundancy, enhancing monitoring capabilities, or developing automated failover processes.
3. Identify Reliability Targets
Establishing reliability targets involves determining the specific objectives that a system or application must meet to ensure continuous operation and data integrity. These targets are usually defined in terms of recovery point objectives and recovery time objectives. RPOs dictate the maximum acceptable amount of data loss measured in time, while RTOs set the maximum acceptable length of time that a service can be down after a failure.
Establishing these parameters helps organizations gauge their disaster recovery strategies’ effectiveness and ensure they align with business continuity requirements. To determine these targets, stakeholders must evaluate the criticality of each system and application, considering factors such as data sensitivity, user impact, and legal or regulatory obligations.
4. Design for Redundancy, Scaling, Self-Preservation, and Self-Healing
Designing a system with redundancy and scaling capabilities is essential for maintaining availability and managing varying loads.
Redundancy involves duplicating critical components or functions so that if one part fails, another can take over without affecting the overall system performance. This can be achieved through multiple data centers, cloud regions, or replication of data and services.
Scaling ensures that resources match the current demand levels, either by scaling out (adding more resources) or scaling up (upgrading existing resources).
Incorporating self-preservation and self-healing mechanisms further improves a system’s resilience.
Self-preservation techniques prevent systems from reaching a state where failure is inevitable by automatically adjusting operations in response to detected issues, such as throttling requests during traffic spikes.
Self-healing capabilities allow systems to recover from failures without human intervention by automatically detecting issues, diagnosing root causes, and executing recovery processes.
5. Establish a Comprehensive Testing Strategy
A well-rounded testing strategy for disaster recovery involves detailed planning and execution to ensure systems can withstand and recover from disruptions. This includes regular simulations of disaster scenarios to validate the effectiveness of recovery procedures and the accuracy of RTO and RPO settings.
By systematically testing different failure modes, organizations can identify gaps in their disaster recovery plan, enabling timely adjustments to strategies, resources, and technologies used in their recovery efforts. Effective testing covers technical aspects as well as operational readiness, ensuring that staff are familiar with disaster recovery processes and can execute them under pressure.
Incorporating a variety of tests, such as tabletop exercises, failover and failback tests, and full-scale drills, helps build confidence in the disaster recovery plan’s reliability. Continuous improvement through regular testing ensures that as systems evolve and new threats emerge, the disaster recovery strategy remains up to date.
Related content: Read our guide to Azure disaster recovery best practices (coming soon)
N2WS: Recover Azure Workloads in Just a Few Clicks
N2WS is a backup and disaster recovery solution fully supporting Microsoft Azure. Using the N2WS Recovery Scenarios feature, you can recover workloads to specific points in time (within a 60 second backup interval) with just a few clicks. This ensures that you can recover mission-critical applications and components without issue.
With our latest release, Recovery Scenarios has been added to Azure for disk storage, VMs and SQL servers. This means you can easily filter your Recovery Scenarios view for Azure, define different sequences of recovery for your protected Azure resources, and then test the recovery sequence with the N2WS Dry Run feature.
Recovery drills can be automatically run on a regular basis, with automated reports sent to team leaders and compliance officers to stay in line with regulatory requirements.
Learn more about N2WS for Azure backup and disaster recovery
See Additional Guides on Key Information Security Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of information security.
AWS Disaster Recovery
Authored by N2W
- [Guide] AWS Disaster Recovery: 4 Approaches and How to Automate DR on AWS
- [Guide] AWS Disaster Recovery Plan: Top Strategies & 10 Tips for Success
- [Product] N2WS | Cloud Backup and Restore
IT Documentation
Authored by Faddom
- [Guide] IT Documentation: 9 Standards and Best Practices
- [Guide] Network Documentation: What to Document & 4 Best Practices
- [Product] Faddom | Instant Application Dependency Mapping Tool
WAF
Authored by Radware