
There are many NoSQL databases available in the market such as HBase, Cassandra, MongoDB, BigTable, Accumulo, Amazon DynamoDB, Voldemort, and so on. Each of these databases has unique features and advantages that need to be suited to an application’s needs. Cassandra is one of the most popular NoSQL databases around. It was developed by Facebook, supports multi-node clusters that are distributed across datacenters, and contains no single master node. This open source NoSQL database has released two versions, so far.
The second one includes quite a few added features that provide better stability and consistency than the previous version. These include scalability, partitioning, consistency, integration with MapReduce, distribution, and more. In addition, it is very important to understand that Cassandra uses a tunable consistency model. In this two part series, we will introduce Cassandra’s architecture to you and describe its inherent backup mechanism for a single and multi node Cassandra setup on AWS cloud.
Cassandra Node-Based Architecture
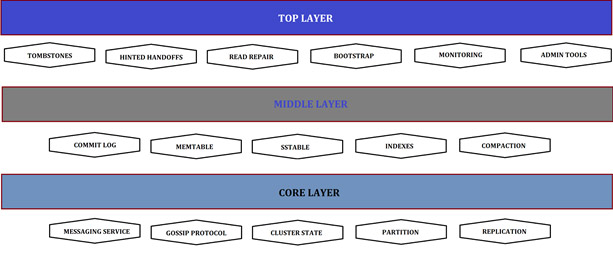
Cassandra architecture is known as ‘masterless’ architecture because it treats all nodes the same—there is no master node. Cassandra uses a peer-to-peer Gossip protocol that helps keep the nodes in sync. Cassandra’s node-based architecture does not have a special host to coordinate activities, which means there is no single point of failure. Therefore, Cassandra’s node-based architecture is easier to operate and maintain because all of the nodes are the same.
- Commit Log, Memtable, SStable: Cassandra provides durability by logging every record in its Commit Log before writing to Memtables. This architecture helps with crash-recovery if one of the node clusters goes down. Whenever the number of records in the Memtable files reaches a certain threshold, all of the contents are flushed and written to a file called SSTable, which is maintained on disk.
- Hinted Handoff Cassandra nodes work in a ring and no single node is considered to be a point of failure. Hinted handoff is a feature that helps optimize the consistency and anti-entropy of Cassandra clusters with information about the write requests for bad nodes.You can enable or disable hinted handoff in the ‘cassandra.yaml’ file. If hinted handoff is enabled, the coordinator stores a hint about dead replicas during writes in the local system. When one of the nodes goes down, hinted handoff will accept a replica from a successful write operation, indicating that a certain write operation needs to be rewritten due to the unavailability of one of the nodes. Hinted handoff does not guarantee successful write operations unless the application has set the consistency level to ‘ANY’.
- Replication Cassandra replication provides reliability and fault tolerance by storing copies of data on multiple nodes. You need to configure the number of replicas needed when you create a keyspace and store each row based on the replica’s row key. The total number of replicas across the Cassandra cluster is known as a replication factor.
Below are two strategies for replication.
- Simple Replication Strategy: This uses a single datacenter cluster. Cassandra places the first replica on one of the nodes that is determined by the partitioners . Then, moving clockwise, the following replicas are placed on the next cluster’s nodes in the ring without the rack or datacenter location.
- Network Topology Strategy: This is used when a cluster is set up across multiple datacenters. There are two common ways of configuring multiple datacenter clusters:
- Two replicas in each datacenter
- Three replicas in each datacenter
How-To Maintain Backup and Recovery
In this section, we will talk about an inherent mechanism offered by Cassandra for backup and system recovery.
- Maintain with Nodetool:
- View the cluster as well as understand and modify its activity
- Monitor the cluster and view accompanying statistics
- View the key-ranges each node maintains
- Move data from one node to another
- Decommission nodes
- Repair nodes
- Backup with SnapshotsThe purpose of snapshots is to make a copy of some or all of the keyspaces in a node and save it to what is essentially a separate database file.The commit log is not part of snapshots. Only flushed data is part of the backup. You can use the following command to take snapshots.$ bin/nodetool -h <hostname> snapshotThis command takes snapshots of a single keyspace:
 You can take snapshots based on keyspaces too. For example, let’s say we created a keyspace that contains all of the files that you want to back up. You then take a snapshot of the keyspace. That snapshot can be used to restore the backed up keyspaces later on, if required, in case of a failure.
You can take snapshots based on keyspaces too. For example, let’s say we created a keyspace that contains all of the files that you want to back up. You then take a snapshot of the keyspace. That snapshot can be used to restore the backed up keyspaces later on, if required, in case of a failure. $ bin/nodetool -h snapshot Keyspace1 The command above allows you to take snapshots for the provided keyspace.
$ bin/nodetool -h snapshot Keyspace1 The command above allows you to take snapshots for the provided keyspace.  Be sure to check the keyspace authentication.
Be sure to check the keyspace authentication. 

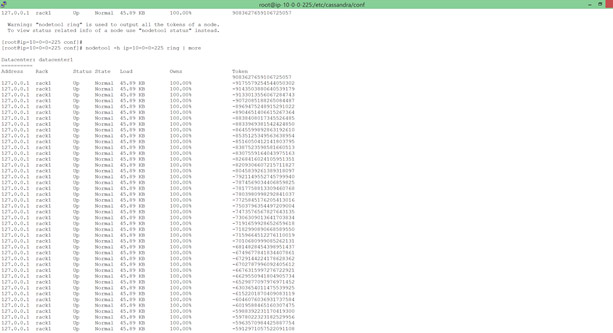
Nodetool is a command-based utility that is provided by Cassandra to manage clusters. It allows you to: Nodetool is shipped with Cassandra and can be found in the directory ‘<cassandra-home>/bin’. Examples: $ bin/nodetool -h <hostname> info The Nodetool command above connects with a single node and gets basic data about its current state. You need to choose a hostname as an address for the information. Ring: $ bin/nodetool -h ring The command above is used to determine which nodes are in your ring as well as their state. Statistics: With Nodetool, you can collect comprehensive statistics about the state of your server all the way down to the data level. You can gather:
- cfstats – which provide an overview of each column family
- tpstats – which provide information about the thread pools that Cassandra maintains
Restore with Snapshots In the previous section, we showed you how to backup data using snapshots. Now, we will try to restore the same data that was backed up using Cassandra’s inherent restore mechanism. Simply follow the steps below:
- For a single node cluster, first shut down the node
- Remove the old SSTable and commit log
- >Copy data from your snapshot directory to your regular directory.

Now check the status of the node using Nodetool: There you have it! A quick way to backup and restore a Cassandra database hosted on AWS using inherent Cassandra mechanisms. In the next article, we will show you how AWS can help you achieve crash consistent and faster DB backup.
