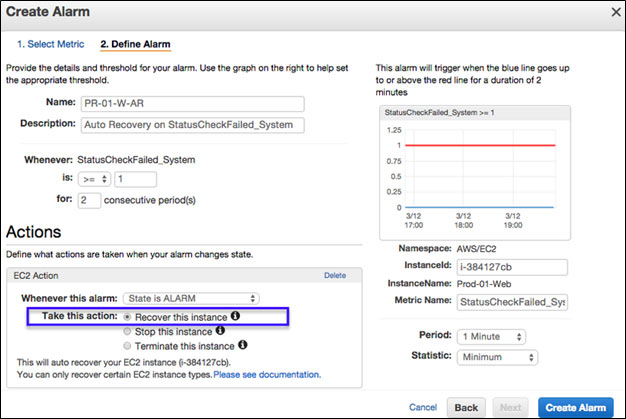
When trying to build a reliable network, you must plan and design for inevitable system errors. Even with today’s advances in technology, failures still occur in hardware and/or software. To handle these challenges, Amazon introduced a solution in January that continues to show the robustness of their cloud. Amazon’s feature for EC2 instances allows for auto recovery, which helps identify failures in an instance and performs automatic recovery actions using a pre-saved instance of the system. Let’s take a look at how this new feature works as well as its potential issues.
How Does It Work?
While running an EC2 instance, there are a series of system status checks (using AWS CloudWatch) that monitor the instance as well as any components that are necessary for the instance to function. These checks look at a number of measures, including network connectivity performance, physical software crashes, and hardware functionality. When one of the system status checks fails, you can restart the instance on new virtual hardware, but auto recovery will not recover the EBS volume to the time before the failure occurred. Note that you have to set up auto recovery for existing instances in order for it to work. Additionally, the newly launched instance will have the same ID, private IP address and metadata, though it will get a new public IP address. Only newer instance types such as C4 and T2 are supported by auto recovery, the more classic types are not. Additional limitations are indicated in the AWS documentation. Auto recovery settings can be found in the EC2 instance CloudWatch preference window: