So why use disk arrays on EC2 at all?
There are two main reasons:
- EBS volumes are currently limited to 1TB. If you need a volume larger than 1TB you’ll need to create a disk array to concatenate multiple EBS volumes.
- By using striping, you can leverage concurrency of IO operations (i.e. read and write) to increase performance. By creating striped disk arrays with IOPS EBS volumes, you can reach very high IO throughput for critical applications.
Understanding the Storage Stack
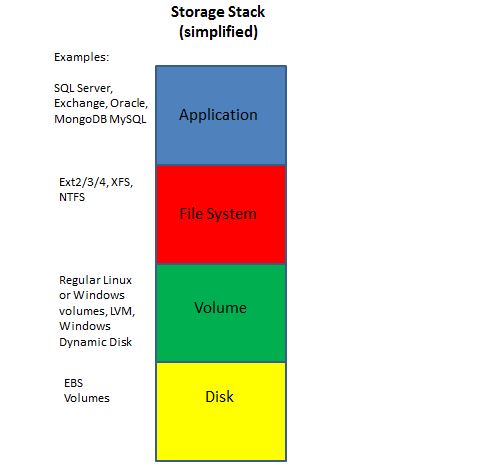
The storage stack contains different levels built on one another. Each level is oblivious of the implementation of the level beneath it. Here is a simplified description of the storage stack:
So, an application can open a file and write to it, but has no knowledge as to how the file system will represent that file on the volume. It has no idea what write size the file system is using: the application can write a 10-byte string to a file without knowing that the file system will initiate a write request of 4KB, because that is the minimal write size.
Underneath it, the file system may write a 4kb chunk of data, now knowing that the volume will use a 64kb block size for it. A volume doesn’t know if the disk underneath is a physical disk or a network-attached disk, nor should it care. When a volume spans multiple disks and the file system performs a write operation, the volume manager may split that write between multiple disks. In the case of EBS volumes, this means that a file can be spread across more than one EBS volume, and a single application write operation can end up as multiple write operations to multiple EBS volumes.
Challenges for Disk Array Backup
File-level backup solutions are not affected by disk arrays and volume managers. They work with the file system, just like the application itself. They don’t know and don’t care how the storage stack is implemented beneath them. Block-level backup solutions can often be more powerful in terms of backup and recovery times. However, with disk arrays and block-level backup solutions the situation is different: if you want to use EBS snapshots to backup a disk array, you face the challenge of keeping snapshots consistent. To make sure the backup of a disk array is consistent you need snapshots of all the underlying EBS volumes at the exact same time.
AWS APIs do not currently offer this functionality, meaning that you can’t take snapshots of multiple EBS volumes at the exact same point in time. However, if you take the snapshots with a small time gap between them, a number of problems can arise. For example, if an application is in the middle of a write operation, it is possible that that operation was writing to multiple EBS volumes. It’s possible that the write operation had already completed on one EBS volume, was in the middle of an operation on another, and didn’t even start on the third. The complete volume, assembled later from snapshots of the different EBS volumes, will be corrupted. In the next part of this post, Disk Array Backup on EC2 Part II: Consistency Issues, we will deal with different solutions to this problem, and how to implement them in different environments like Linux and Windows.